It’s an open secret that you can follow YouTube channels through RSS, it’s also something I’ve covered on this blog before. What I wasn’t aware of until recently was how difficult it could be to find the RSS feed for a YouTube channel. I mistakenly thought any RSS service could discover the feed URL from a YouTube channel, but after chatting with Andreas (82Mhz) on Mastodon we discovered this wasn’t the case. It was just a feature of Miniflux which is the RSS service and client that I used.
Read more...
Project
After recently discovering Untappd’s RSS feed, I set out to find if AniList had the same hidden feature so I could ingest activity logs to the homepage of pesky.moe. After much searching I found that this wasn’t the case, but AniList did have a an open GraphQL API! I was able to use this to get my user’s activity and pass them along when generating my homepage.
This wasn’t enough. I have the urge to RSS all the things! I then set about creating an RSS feed from my users activity that I can fetch via the API. It wasn’t difficult given that I could reuse the code I had previously written both to fetch the activity and create RSS feeds from my other projects. Putting it all together I open-sourced the repository last weekend along with publishing the feed.
Read more...
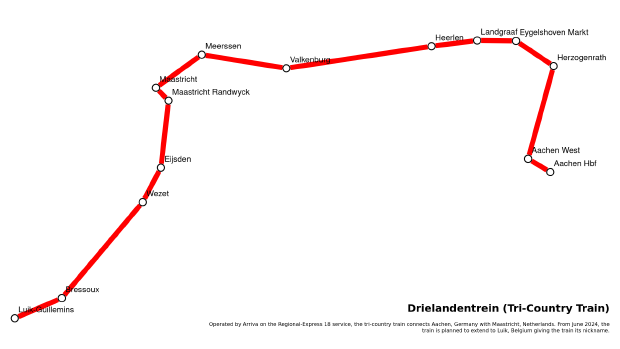
Since I’ve begun blogging semi-regularly I’ve learned that having visuals helps especially when it comes to talking about different locations and their relation to each other. It can be difficult to judge the space and distance between two streets in a city or two cities in a country without some familiarity with the location. A problem I come across frequently when reading transit-related articles and blogs. It’s for this reason I try to include maps in my transport-related posts from very early on.
Read more...
This week I open sourced a Terraform project I’ve been using for the past few months. This solution allows the user to schedule the start or stop of EC2 instances in a single AWS account. This schedule is defined through Terraform and created EventBridge Schedulers. This post will be a snapshot in time of how the solutions looks at the time of publishing. An up to date and concise description of the solution can be found on its GitHub page.
Read more...
Web scraping is the act of extracting data from websites. This is a repository of scrapers I’ve built over the years for various websites. They download media files and other data. These scripts exist purely for education purposes.
The scrapers are built using Python 3 and BeautifulSoup which is a library for grabbing and navigating data from HTML and XML files.
The source code can be found on GitHub.
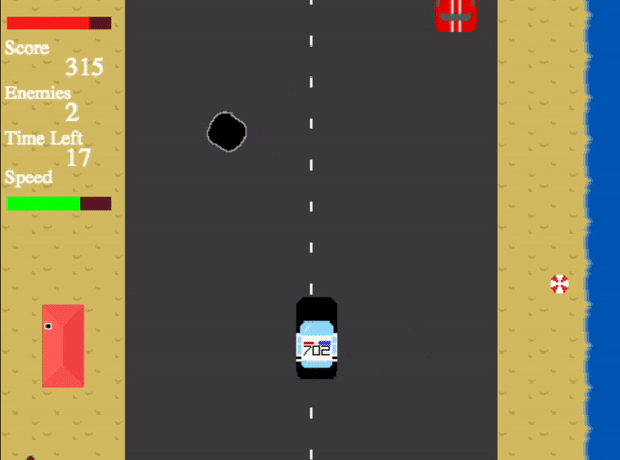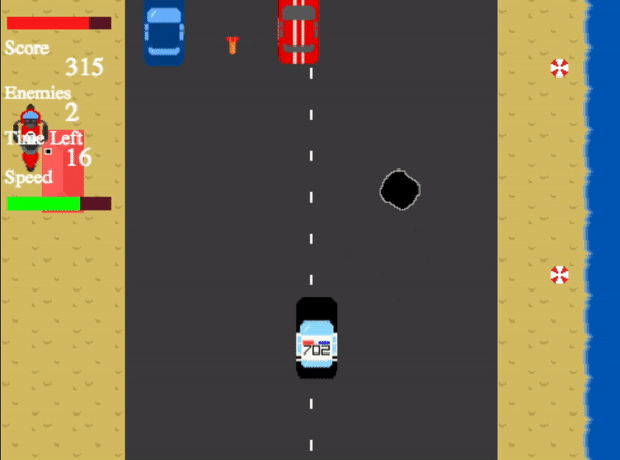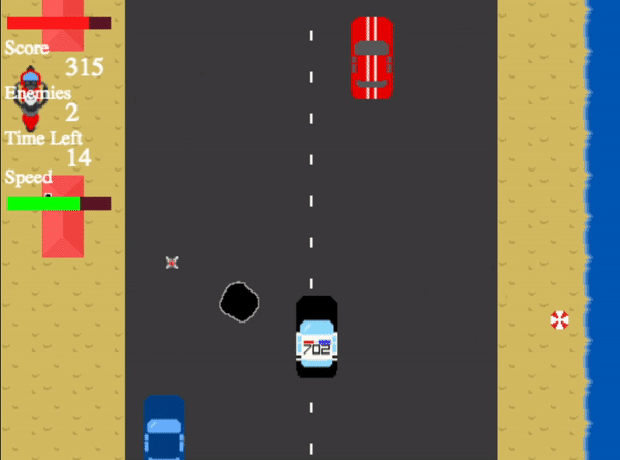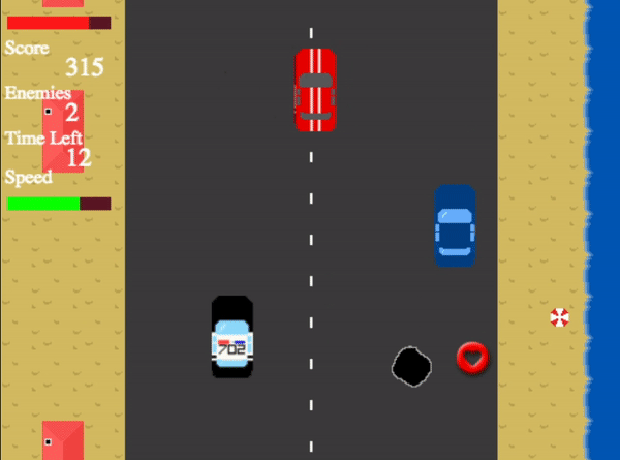
Crime Hunter - Shoot the enemy before they shoot you! A web game built in JavaScript using Phaser
project
This is a web game contains four unique levels, all increasing in difficulty. The main aim of the game is to shoot down the enemy vehicles before they escape you shoot you down first. After the end of each level, the user’s progress is saved so the game can be continued at another time.
Crime Hunter started out as a class group project where I was a developer and graphic designer.
Read more...

This is a Python program to traverse and download posts from subreddits and users on an incremental basis. It also records which posts have been saved so as to only download new submissions.
The program uses multiple methods of extracting data from links posted to Reddit. The Reddit API is used to get submissions from Reddit, the links are then parsed and forwarded to the appropriate extractor. With the API restrictions, if you wish to download more than 1000 submissions, the Pushshift API is used for the remainder of the submissions. Images from Imgur are downloaded preserving the original descriptions and title. If the link is not supported by any in-built scrapers it is passed into the youtube_dl library with its large number of information extractors focused on video streaming sites.
Read more...